So-called “neural networks” are extremely expensive, poorly understood, unfixably unreliable, deceptive, data hungry, and inherently limited in capabilities.
In short: they are bad.
Lies, damned lies, and machine learning
Many confusions result from the vagueness of the terms “statistics,” “machine learning,” and “artificial intelligence.” The relationships between these are unclear and have shifted over the years.
Traditional statistical methods have the virtue of simplicity. It is comparatively easy to understand what they do, when they will work, and why. However, the circumstances in which they do work are quite restricted.
Traditional statistical methods come with mathematical guarantees: if certain conditions hold, the output of a particular sort of statistical analysis will meaningful in a particular way. Those conditions almost never do hold in the real world, so statistical analyses are almost never “correct.” As a result, it is easy to fool yourself, and others, with statistics.1 Good use of statistics requires meta-rational judgement: informal reasoning about whether a method, whose use is formally mistaken, may give adequate guidance for particular purposes in a particular context.2 It also requires on-going monitoring, after a method is put into routine practice in a particular context, to keep checking whether it is working well enough.
These requirements are not widely understood, so traditional statistical methods are often misused. Sometimes that has catastrophic consequences, as in the 2008 Great Financial Crisis and in the current medical science replication crisis.
Machine learning was once considered a small subfield within artificial intelligence. During the 1990-2000s AI Winter, machine learning split off as a separate field. It studied statistics-like data analysis methods that lack theoretical justification. It mostly avoided reference to artificial intelligence. Recently, “artificial intelligence” has come to be seen as a subfield within machine learning.
“Machine learning” methods are applicable to “messy” or “complex” datasets, meaning ones without the simple properties required to make traditional methods work. In this sense, they are “more powerful.” However, there’s no general reason they ought to work when they do, so it’s difficult to guess whether they will be adequate for particular uses.
It is also difficult to tell whether they are working. With traditional statistical methods, there are principled ways of checking adequacy and understanding failures. Machine learning practice substitutes a purely empirical test: how well does a model predict data collected—perhaps haphazardly—in the past?3
That is justifiable only if future data will be sufficiently similar to that already collected. It may be difficult or impossible to reason about whether that will be true. It is hard to know what the future will be like even in general; and what measure of “similarity” is relevant depends on the specific task and specific model.
This makes it even easier to fool yourself with machine learning than with traditional statistics. It implies that responsible use requires near-paranoid distrust, and still greater commitment to on-going monitoring of accuracy.
Neural networks and artificial intelligence

“Artificial intelligence” is currently almost synonymous with applications of a single method, error backpropagation. That is a statistical method misleadingly described as “neural networks” or “deep learning.” Backpropagation is currently applicable to tasks amenable to no other known method, but suffers major drawbacks.
“Neural networks” are even more difficult to reason about than other machine learning methods. That makes them power tools for self-deception. Mainly, researchers don’t even try to understand their operation. The “Backpropaganda” chapter explains how they justify that.
I often put “neural networks” in scare quotes because the term is misleading: they have almost nothing to do with networks of neurons in the brain. Confusion about this is a major reason artificial “neural networks” became popular, despite their serious inherent defects. I will often refer to them as backprop networks, for that reason.4 (“Backprop” is a common shorthand for “backpropagation.”)
The upcoming “Engineering fiasco” section argues that using them is often irresponsible. They should be restricted to applications in which other mechanisms provide safety backstops, and as much as possible should be avoided altogether.
Traditionally, the machine learning field treated neural networks as one method among many—and not usually as the leading technique. However, they are now considered more powerful than any other known method, in being applicable to a wider range of data. Recent progress with backpropagation has led many researchers to believe it is capable of realizing the dream of advanced artificial intelligence. AI is now taken to be a subset of its applications.
Equating artificial intelligence with backpropagation creates two sorts of distortions. Statistical methods (including backpropagation) are inherently limited in ways that people (and some other AI methods) aren’t. And, many applications of neural networks don’t reasonably count as AI. When I express skepticism about applications of artificial intelligence, people often cite applications of neural networks instead.
Neurofuzzy thinking
To illustrate the non-equivalence, rice cookers are an extreme example. Some of these inexpensive home kitchen appliances contain neural networks. According to the manufacturer Zojirushi, who brands them as “neurofuzzy,” that “allows the rice cooker to ‘think’ for itself and make fine adjustments to temperature and heating time to cook perfect rice every time.” This is “thinking” or “intelligence” only in the loosest, most metaphorical sense.
Although I lack expert knowledge of rice cooking, I expect well-understood traditional control theory methods would work as well as a “neural network.” Those would be simpler, and they come with mathematical guarantees that would give reasonable confidence that they’d work.
I expect the rice cooker designers weren’t idiots, and understood this. So why did they use a neural network?
- Presumably it’s largely marketing hype.
- Maybe it isn’t even true; quite often companies claim to “use AI” when they don’t at all. It helps create a positive public image.
- Maybe there is a “neural network” in there, because marketing people decided that would sell it, and they told the engineers to put one in.
- Or maybe it was more fun for the engineers to use a sexy “artificial intelligence” method than boring old control theory.
If the rice cooker does have a neural network, I expect it’s a very small one. I expect the designers either hand-wired it, or they reverse engineered it from the results of a “machine learning” process, making sure it does something sane.
I also expect they put safety mechanisms around the neural network. Those would ensure that, regardless of whatever the neural network does, the cooker won’t explode. These are the precautions everyone ought to apply before using neural networks for anything more than entertainment.
Revolutionizing what, specifically?
It’s common to read that “applications of artificial intelligence are revolutionizing a host of industries,” but on examination it turns out that:
- most practical applications don’t involve anything most people would count as “intelligence”
- most are not revolutions technically or economically; many have smaller total addressable markets even than rice cookers
- many are unsafe and irresponsible
- many might work better using some better-understood, more reliable method than neural networks.
In most situations, well-understood traditional statistical methods, or machine learning methods that are less expensive and more understandable, work better.5 Plausibly, many times when people try backpropagation first (misguided by hype), and it works well enough to get put into use, alternatives would have worked better. When backpropagation succeeds quickly, it may be because the problem is trivial: for example, nearly-enough piecewise linear. In such cases, backpropagation is expensive overkill.
For some tasks, however, backpropagation can produce astounding results that no other current method can approach.
Gradient Dissent explains the inherent risks in using backpropagation, suggests ways of ameliorating them, and recommends developing better alternatives.
Backprop: an engineering fiasco
Backpropagation requires masses of supercomputer time, is difficult or impossible to get to work for most tasks, and is inherently unreliable—and therefore unsafe and unsuitable for most purposes.
From an engineering point of view, “neural” networks are awful:
- Inefficient: They are extremely computationally expensive.
- Difficult to make work: Getting adequate results in new real-world applications is often impossible, and usually takes person-years of work by expensive specialists if it succeeds.
- Unreliable: Backprop networks are unavoidably, unfixably unreliable, and therefore unacceptably unsafe for most applications.
The next few sections explain why.
We would reject any other technology that violated basic engineering criteria so completely. “Backpropaganda,” the second chapter of Gradient Dissent, explains some reasons—bad ones—tech companies make an exception.
But, it’s also true that backprop networks can sometimes do things that no other current technology can do at all. Even if they usually do them badly, some outputs are astonishing. That is what makes current AI exciting. Most of the time the image generator DALL-E doesn’t give you what you asked for, and getting it to give you exactly what you want is usually impossible. With a lot of work, though, it may eventually give you something close enough for your purposes; and also many of the totally wrong things it gives you are amazing, even if people in them have six fingers. This is fantastic for a toy, and for demo hype, perhaps for commercial illustration generation if someone counts fingers before publication, and unacceptable for engineering applications.
Since backprop networks are inherently unreliable, they should be used only as a last resort, and only when:
- Bad outputs are not costly, risky, or harmful; or
- Each output can be checked by a competent, motivated human; or
- You can drive the error rate so far down that bad outputs nearly never occur in practice, and you have justified confidence that this will remain true in the face of the volatility, uncertainty, complexity, and ambiguity of the situations where the system will be used.
Fortunately, most deployed systems do fit one of the first two categories (and often both). (Deployment means “putting into regular use.”) For instance:
-
Backprop networks are used for image enhancement in digital photography; when they screw up, it’s usually either obvious to the photographer or inconsequential
-
Image generators such as DALL-E are for entertainment and aesthetic purposes only, and therefore mostly harmless—so far. (There are increasing concerns about fake photos and videos used in scams and propaganda, and about job losses for artists and photographers.)
-
The outputs of program synthesis systems such as Copilot are useful although unreliable, so they depend on expensive, highly-trained experts (software engineers) to check and correct each output.
I’m not sure there are any applications in the third category; the next section explains why.
DO NOT connect artificial neurons to heavy machinery.6
Unfortunately, idiots do connect backprop networks to heavy machinery, metaphorically speaking at least, and that should be condemned. Applications in policing, criminal justice, and the military are particularly concerning. Sayash Kapoor and Arvind Narayanan’s “The bait and switch behind AI risk prediction tools” discusses several other interesting real-world examples.7
The internet is, in some metaphorical sense, the heaviest machinery we’ve got. Connecting text generators to it has several potentially catastrophic risks (discussed in “Mistrust machine learning” in Better without AI). So far, the only significant harm has been the swamping of the web with AI-generated spam. That has made Google Search much less useful than it had been. Ironically, one of the main uses for ChatGPT has been as a web search replacement.
Backprop networks are deceptive
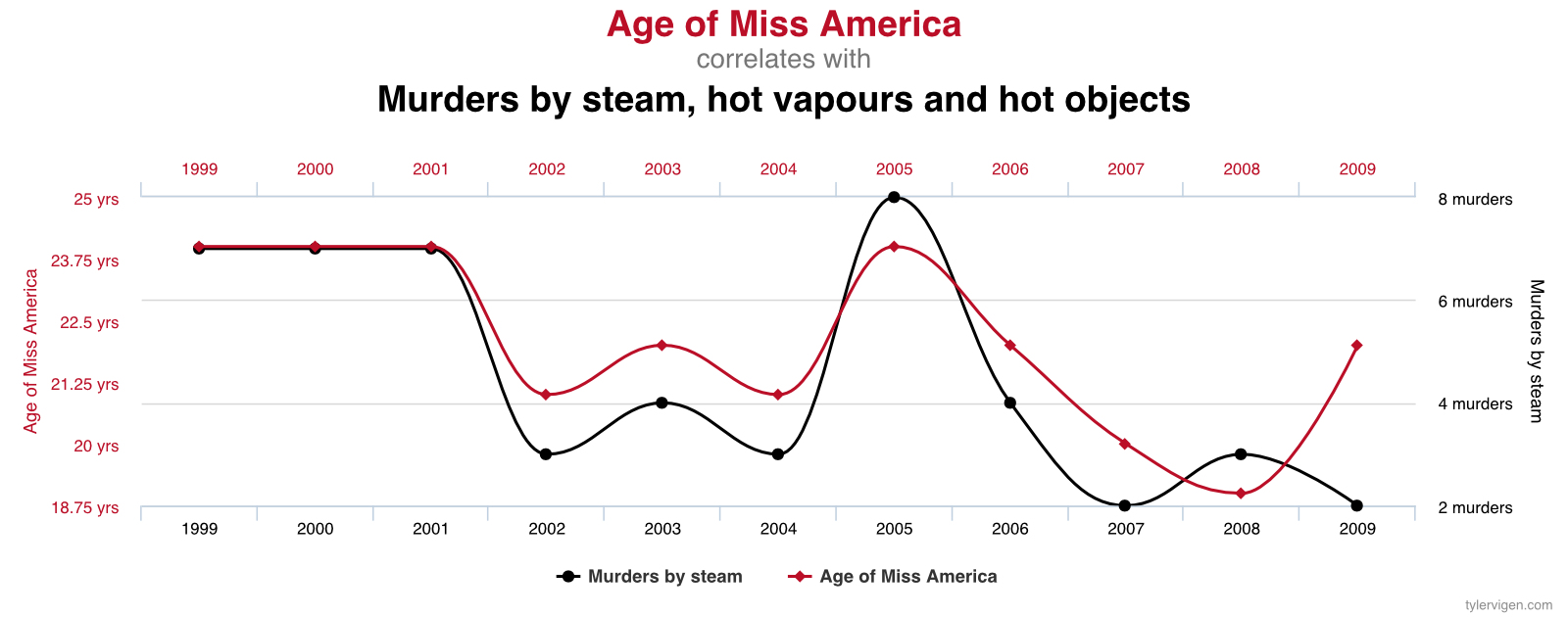
Backprop networks frequently fool their creators into believing they can do things they can’t. This is not due to deliberate intent on their part. It’s due to non-obvious properties of statistical behavior that are hard to detect and hard to overcome.
Backpropagation is a method of training a network to perform a particular sort of prediction by presenting it with a set of known-correct input/output pairs. These are called the training data. After training finishes, the network can be put into use, where it is supposed to predict outputs corresponding to new inputs. Recommender AIs predict whether you will click on an advertisement. GPTs, the technology powering text generators, predict a natural-sounding response to your prompt.
Backpropagation frequently finds ways of “cheating” by exploiting spurious correlations in the training data. Those are accidental patterns that show up consistently in the training data, but that don’t hold true where the network will be used. (The chart above is a funny example.8) It is often easier for backprop to find a spurious correlation in training data that only accidentally “predicts” the past than for it to solve the problem the creator cared about.
When backprop exploits spurious correlations, it may give excellent results during training—and fail catastrophically when put into use. Unfortunately, it can be extremely difficult to determine whether it has deceived you in this way; and it can be extremely difficult to prevent it from doing so.
Here’s a simplified example. If you want a supermarket warehouse AI that can tell whether something is a banana or an eggplant, you can collect lots of pictures of each, and train a network to say which ones are which. Then you can test it on some pictures it hasn’t seen before, and it may prove perfectly reliable. Success, hooray!
But after it’s installed in a supermarket warehouse, when it sees an overripe banana that has turned purple, it’s likely to say it’s an eggplant.
If you had no overripe banana pictures in your original collection, you’d never notice that backprop had fooled you. You thought it learned what bananas looked like, but it only learned to output “banana” when it saw yellow, and “eggplant” when it saw purple. It found a spurious correlation. That was a pattern that held in the training data as an accidental consequence of the way they were collected, but that doesn’t hold reliably in the real world. The problem it solved was easier than the one you wanted it to solve, so that’s what it did.
This type of failure occurs almost always. Detecting it, and finding work-arounds, is much of the work of building practical AI systems.
The limits of interpolation
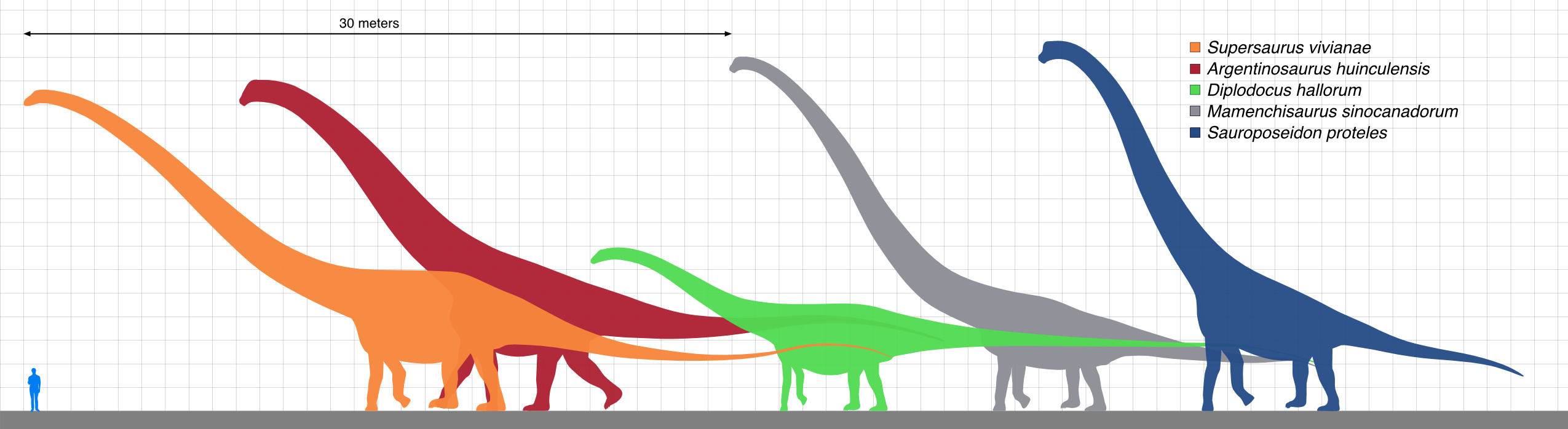
Backprop networks work by interpolation: guessing answers based on similar cases in its training data. They are inherently unreliable when given inputs unlike any they were trained on.
Network training is metaphorically similar to learning how things are likely to go based on experience. The training data are like past experiences. They are situations (inputs) together with their results (outputs). Recommender AIs are trained on databases of past events in which people with particular traits did or didn’t click on particular ads. Text generators are trained on databases of bits of previously-written text and what came next.
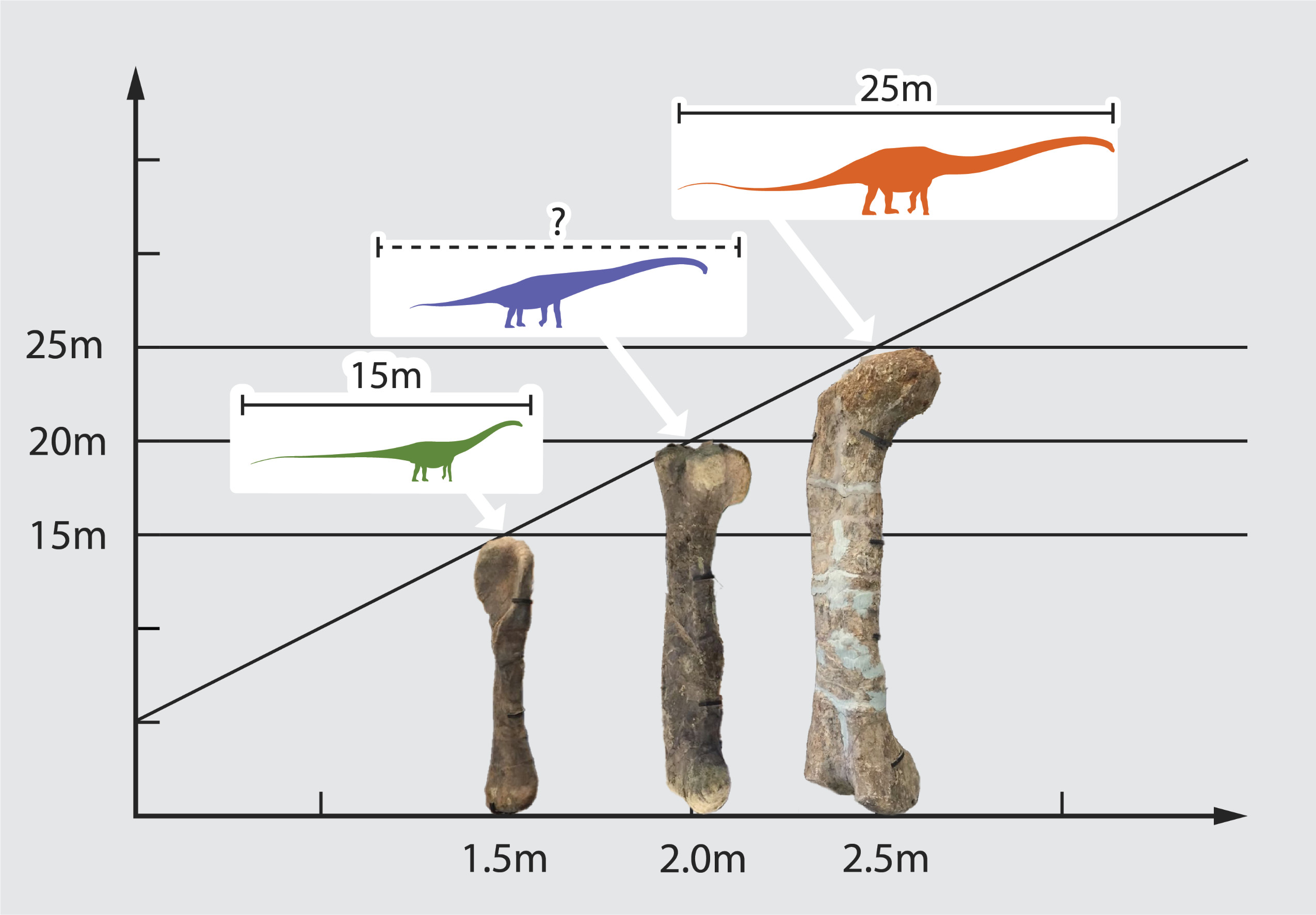
“Interpolation” means guessing, when given a particular input that is not in the training data, that the correct output will be similar to the training outputs for the most similar training inputs. For example, paleontologists can estimate the length of sauropod dinosaur species from a single femur, if that’s the only fossil bone found.9 For some other species, there are complete fossil skeletons of known total length and femur length. Given a new femur 2.0 meters long, it’s reasonable to estimate a total length of 20 meters, based on the nearest two species, one with a 1.5 meter femur and 15 meter total length, and another with a 2.5 meter femur and 25 meter total length. This is a linear interpolation—you just draw a line between (1.5, 15) and (2.5, 25), and find where 2.0 lies on it.10
Some people dismiss backprop networks as just doing interpolation. This is a mistake, however: the word “just” minimizes what interpolation can do. Networks interpolate based on “similar” training data; but similar how? In the case of femur lengths, “similar” is just numerical closeness.11 But what makes two sentences similar? “The quokka bit the mayor” is similar to “The mayor bit the quokka” in one sense, and similar to “The head of the town council was savaged by an illegal pet marsupial” in another. How would you rate those similarities numerically?
Finding a task-relevant measure of similarity accounts for backpropagation’s power. Training creates a “latent space,” in which numerical closeness equates to similarity for prediction. “The quokka bit the mayor” and “The mayor bit the quokka” have identical words in a slightly different order. However, the distance between them in a text generator’s latent space should be large, because what follows is likely to be quite different. On the other hand, “The head of the town council was savaged by an illegal pet marsupial” should be quite close to “The quokka bit the mayor,” even though they share only one word. The sentences mean much the same thing, and can plausibly be followed by most of the same things.
Backprop networks “just” do linear interpolation in latent space. But the results can seem like magic, or at least “intelligence,” if training manages to get meaningfully similar inputs close to each other in latent space. You can think of the latent space as abstracting a task-relevant ontology of categories from apparent features. That predicts task-relevant similarity.
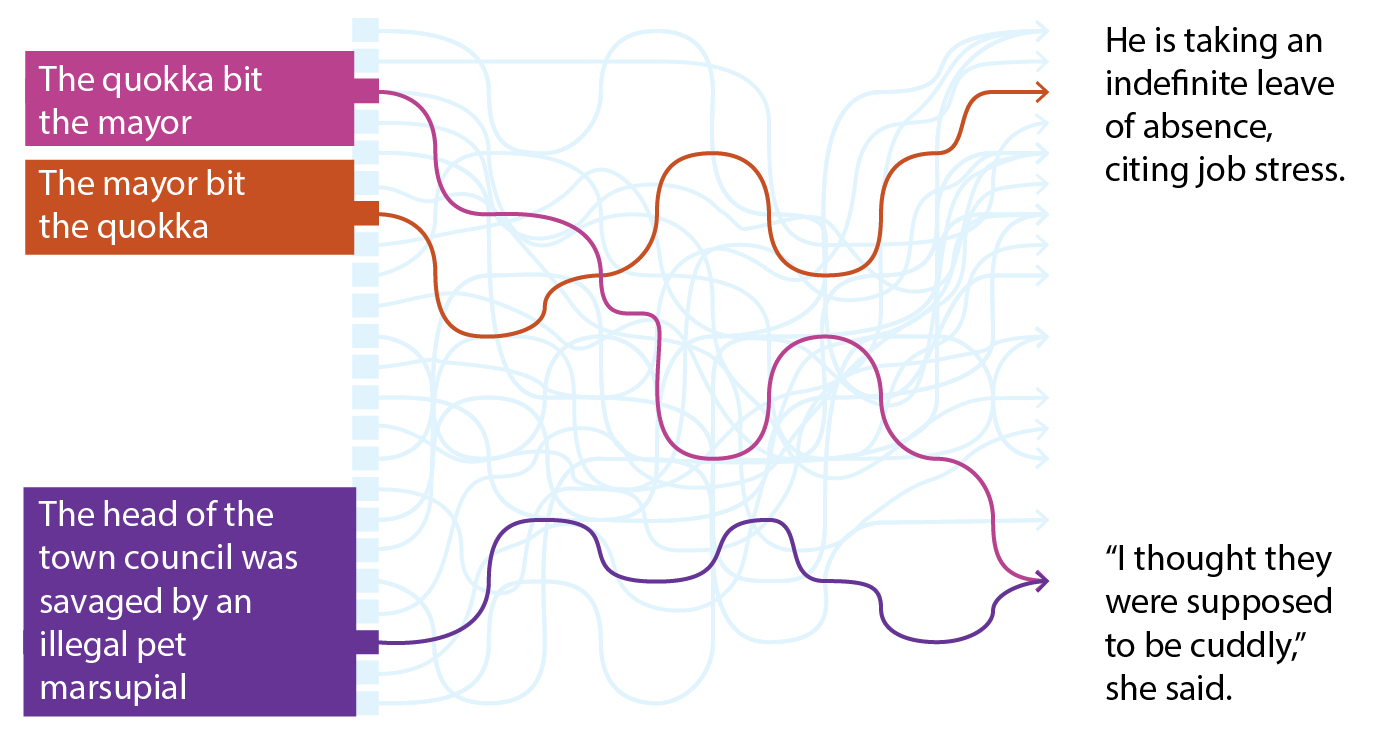
Then it is apparent that good performance requires dense sampling in the latent space. Latent space is unimaginably huge and weird. Interpolation is linear, but latent space is highly nonlinear. Superficially similar inputs may correspond to very different places in latent space (as with swapping the quokka and the mayor).12 Given a new prompt, unless there was some training input that was nearby in latent space, the network’s output will likely be nearly random. This is why backprop depends on “big data”—vastly more than people require to learn anything.
To get a sense of latent space, check out the YouTube video “Latent Space Walk.”13 It “walks” through a tiny bit of the latent space of an image generator network. Each point in latent space corresponds to a complete image. Each frame in the movie is generated from a single point in latent space. Each next frame is generated from a latent space point close to that of the previous one. So, following a path through latent space, generating a new image at tiny regular intervals, produces a shifting series of seeming landscape paintings, in a consistent style, but with gradually changing contents.
Depending on how abstract and meaningful the latent space is, “just” interpolating can be extremely impressive. Some people equate abstraction ability with intelligence itself. I think that’s not usually a good way of understanding it, but it’s not silly either.
Another latent space walk, at youtube.com/watch?v=YnXiM97ZvOM, takes you through a part of the space based on headshots. The moving tiny x in the right-hand pane shows the path taken through the space. You can see in the left-hand pane how the network has abstracted meaningful facial qualities from its training data.
Nevertheless, by Occam’s Razor, we should assume as little abstraction as necessary to explain a network’s behavior. We should expect that, typically, outputs are similar to ones in a training example, or a few training examples stitched together.
This usually seems to be the case for both text and image generators. It’s amazing how well they work, but a general sense of how they work is not extremely mysterious when examined. The “how well” depends on mind-boggling quantities of training data—enough to fill the latent space. Current text generators ingest trillions of words in training, equivalent to tens of millions of books. Our intuitions about how smart they are get distorted because we literally cannot imagine what it would be like to have read and memorized that much.
It’s also not mysterious how badly backprop systems work sometimes. Similarity in their latent space is only intermittently similar to our notions of similarity. If you ask DALL-E for a photorealistic image of Vladimir Putin rollerskating in Red Square, you may get something that is astonishingly like that, except that he has three legs. We think having three legs makes someone extremely dissimilar to Putin, but image generators don’t. (That is why they work best for surreal fantasy scenes.)
Brittleness out of distribution
Some good arguments against the possibility of inherently safe AI turn on the real world situation in which a system is used being significantly different from its training data. Then it will encounter out of distribution inputs, things unlike those it has seen before, and its behavior will be inherently unpredictable—no matter how well-behaved it was during training. It will be forced to extrapolate, not interpolate.
We can form a somewhat deeper understanding of the “purple banana” problem in terms of the limits of interpolation. What would be a good dinosaur length estimate if you found a 7 meter femur? This is termed an “out of distribution” input: nothing anywhere near that big has been recorded previously. You could scale up linearly and estimate 70 meters, but you’d probably be wrong.
In this case, the linear estimate would not be an interpolation (between known cases), but an extrapolation (outside the range of known cases). Extrapolation is highly unreliable. It’s likely that a dinosaur with that dissimilar femur had a dissimilar body shape as well: proportionately longer legs, maybe for a different gait, evolved for different terrain.
Any method that works by interpolation is vulnerable to this critique—although mainstream statistical methods fail in ways that are better understood, and therefore easier to mitigate against, than those of machine learning.
On this basis, we should expect poor network performance when there’s nothing relevantly similar in its training data. We should assume any AI system using statistical methods will be unsafe in open-ended real world situations, which are vastly weirder and more complicated than any training data set.14 And, this has been the common experience.15
This makes me skeptical of “alignment” approaches based on “training” backprop networks to behave well. Reinforcement learning with human feedback (RLHF) uses standard machine learning methods to prevent text generators from producing outputs considered “bad”—because they are offensive or unhelpful, for instance. It trains an existing generator on a database of “good” and “bad” user interactions.
RLHF has been critical for the success of ChatGPT and similar systems, because negative PR from “bad” outputs had been a major obstacle previously. (Recall from “Create a negative public image for AI” that AI was, and arguably still is, mainly a PR strategy for the advertising industry.)
RLHF is further positioned by chatbot providers as an alignment method for AI safety, which is disingenuous. It addresses the most publicized, but least significant, AI ethics concerns. It does not address AI safety—in the sense of “make sure it doesn’t kill people”—at all. So far, it seems that chatbots are not a serious AI safety risk. However, describing RLHF as an alignment method may cause unwarranted complacency. Although RLHF makes “bad” outputs much less likely, chatbots still frequently produce them.16
Like all machine learning methods, RLHF is inherently unreliable, only probabilistically effective, and should not be used when “bad” outputs can be seriously harmful. Even if you drive the probability of badness down to levels you consider acceptable during training, bad behavior in the real world remains unboundedly likely, due to the distributions of inputs differing from those in the training data. Nobody can think of all the bad things an AI system might do, in order to train it not to.
Engineering often aims for graceful degradation. When a machine fails, due to internal breakage or because its environment is not as expected, it should either grind to a gradual stop, or continue to operate but less well. It should not explode, melt down, or spew toxic chemicals. Text generators often do not degrade gracefully; when they fail, it can be by spewing deceptively plausible falsehoods, absurd nonsense, or toxic language.
Is it feasible to get them to just notice when an input is out of distribution and refuse to proceed? As with the previous approach, this might help somewhat, but if the noticing method is also based on backprop, it won’t be reliable either. And, its similarity metric will be somewhat bizarre (“person with three legs looks like Putin”), so its idea of what’s out of distribution will be off.
The opposite of graceful, gradual degradation is often termed “brittleness.” A brittle material doesn’t bend under stress; it suddenly shatters.
Brittleness is an obstacle to deployment, if it’s taken seriously. This is good, if you assume by default that any new AI system is dangerous and shouldn’t be deployed (as I do). Brittleness is bad, if you expect idiots to nevertheless connect it to heavy machinery (as they do).
Beyond interpolation: reasoning?
So if people are “really” intelligent, how do we deal with stuff “way out of the training distribution”? In other words, situations unlike any we’ve seen before?17 What do we do that isn’t mere interpolation?
The standard answer is that we apply reasoning. We can use a chain of deductive or causal logic to figure out a correct answer to a novel problem, or an effective course of action in a novel situation. For example, we might suppose that scaling up a sauropod linearly to 70 meters is implausible because weight grows as the cube of length. We might, further, reason about different body plans that could accommodate a 7 meter femur. We might use mechanical engineering stress analysis techniques to check their plausibility.
Many researchers assert that backprop networks don’t, and maybe can’t, reason logically, which is why they aren’t really intelligent. So, they say, that needs to get fixed somehow—either by coupling the backprop network with a logical reasoning system, or by training the network to reason itself.
This seems dangerous. Backprop networks that flail about more-or-less randomly when they encounter novel situations are bad, but they will destroy the world only by accident: if some idiot connects them to nuclear weapons or to internet advertising platforms or something. That would be unfortunate, but maybe other people will have enough sense to stop them. AI systems that act competently out of distribution are liable to destroy the world on purpose. This is a Scary scenario.
We don’t want AI systems trying to be rational unless we’re confident they will do a good job. “Good” here must be morally as well as cognitively normative. Backprop-based systems probably cannot be reliably rational (in part because they can’t be reliably anything). If they are “trained” into more nearly approximating rationality, and deployed with the expectation that they will be consistently rational, disaster seems likely.
- 1.Hence, “lies, damned lies, and statistics“—attributed to Mark Twain. Also How to Lie with Statistics; and see “Statistics and the replication crisis” at metarationality.com/probabilism-crisis.
- 2.“All models are wrong, but some are useful” was the way George Box famously put it, in “Science and Statistics,” Journal of the American Statistical Association 71:356, 1976.
- 3.A strong, historically important justification for this practice is Leo Breiman’s “Statistical Modeling: The Two Cultures,” Statist. Sci. 16(3): 199-231 (August 2001).
- 4.“Backprop network” is a common usage, but may also be misleading, because backpropagation is not involved in the operation of the network itself.
- 5.When investors or senior management tell a clueful technical team to solve a problem with “AI,” often the engineers use something simpler, cheaper, and more reliable than backpropagation; then report success; and the company touts its “AI solution” to the public. This practice is common enough that the US Federal Trade Commission issued a warning in February 2023 that they would take action against it: “Keep your AI claims in check.” Relevant are Amy A. Winecoff and Elizabeth Anne Watkins’ “Artificial Concepts of Artificial Intelligence” (arXiv:2203.01157v3) and Parmy Olson, “Nearly Half Of All ‘AI Startups’ Are Cashing In On Hype” (Forbes, Mar 4, 2019).
- 6.Automobile driver-assist systems may be an exception—not full self-driving, but the much more limited versions that have been in routine use for several years as of 2023. Arguably those meet all three criteria I listed for safety. They are limited to taking actions (braking and lane-keeping) that are relatively unlikely to be catastrophic even if triggered mistakenly; their error rate has been driven down a long way; they can be overriden immediately, and their outputs must be continuously checked by a competent, motivated human, i.e. an alert driver. Nevertheless, they do sometimes cause fatal accidents, and many drivers choose to disable them.
- 7.AI Snake Oil, Nov 17, 2022.
- 8.The chart is by courtesy of Tyler Vigen under the Creative Commons Attribution 4.0 International license at tylervigen.com/spurious-correlations.
- 9.The sauropod length diagram above is by courtesy of user KoprX under the Creative Commons Attribution-ShareAlike 4.0 International license at https://en.wikipedia.org/wiki/Dinosaur_size#/media/File:Longest_dinosaurs2.svg.
- 10.I picked round numbers to make the answer easy to see, but these are approximately accurate. Sauropods did get quite long and it would be fun to revive some if that becomes possible.
- 11.The diagram of sauropod length interpolation above is by courtesy of Matt Arnold (personal communication).
- 12.The diagram of paths through the backprop network above is by courtesy of Matt Arnold (personal communication).
- 13.At youtube.com/watch?v=bPgwwvjtX_g
- 14.An excellent discussion, with policy recommendations, is Ganguli et al.’s “Predictability and Surprise in Large Generative Models,” arXiv:2202.07785v2, 2022.
- 15.“Models that achieve super-human performance on benchmark tasks (according to the narrow criteria used to define human performance) nonetheless fail on simple challenge examples and falter in real-world scenarios. A substantial part of the problem is that our benchmark tasks are not adequate proxies for the sophisticated and wide-ranging capabilities we are targeting: they contain inadvertent and unwanted statistical and social biases that make them artificially easy and misaligned with our true goals. We believe the time is ripe to radically rethink benchmarking.” Kiela et al., “Dynabench: Rethinking Benchmarking in NLP,” Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, pp. 4110–4124, June 6–11, 2021.
- 16.Casper et al. provide a useful survey of reasons for the inherent inadequacy of RLHF in “Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback,” arXiv:2307.15217v2, 2023.
- 17.There are definitional problems here. What counts as “way out” or “unlike”? These are meaningful only relative to some measure of similarity, for which there is no objectively correct choice. “In distribution” is somewhat conceptually incoherent unless it means “identical to an item in the training data.” It’s metaphorically useful, however, so we can ignore the issue for the purpose of this discussion.